Decision Tree는 overfitting될 가능성이 높다는 약점을 가지고 있습니다. 가지치기를 통해 트리의 최대 높이를 설정해 줄 수 있지만 이로써는 overfitting을 충분히 해결할 수 없습니다. 그러므로 좀더 일반화된 트리를 만드는 방법을 생각해야합니다. 이는 Random Forest(랜덤 포레스트)의 기원이 되는 아이디어입니다. Random forest는 ensemble(앙상블) machine learning 모델입니다. 여러개의 decision tree를 형성하고 새로운 데이터 포인트를 각 트리에 동시에 통과시키며, 각 트리가 분류한 결과에서 투표를 실시하여 가장 많이 득표한 결과를 최종 분류 결과로 선택합니다. 랜덤 포레스트가 생성한 일부 트리는 overfitting될 수 있지만, 많은 수의 트리를 생성함으로써 overfitting이 예측하는데 있어 큰 영향을 미치지 못 하도록 예방합니다.
랜덤 포레스트(Random forest)
앙상블방법 중 확장성이 좋고 사용하기 쉬운 결정 트리 기반 알고리즘이다.
결정 트리의 앙상블(ensemble)
여러 개의 (깊은) 결정 트리를 평균내는 방법이다.
개개의 트리는 분산이 높은 문제가 있지만, 앙상블은 견고한 모델을 만들어
일반화 성능을 높이고 과대적합의 위험을 줄인다.
Random forest process
1. n개의 랜덤한 부트스트랩(bootstrap) 샘플을 뽑는다.(훈련 데이터셋에서 중복을 허용하면서, 랜덤하게 n개의 샘플 선택)
2. 부트스트랩 샘플에서 결정 트리를 학습
a) 중복을 허용하지 않고 랜덤하게 d개의 특성을 선택
b) 정보 이득과 같은 목적 함수를 기준으로 최선의 분할을 만드는 특성을 사용해서 노드를 분할
3. 단계 1~2를 k번 반복한다.
4. 각 트리의 예측을 모아 다수결 투표(majority voting)로 클래스 레이블을 할당한다.
Random forest는 결정 트리만큼 해석이 쉽지는 않지만, 하이퍼 파라미터 튜닝에 많은 노력을 기울이지 않아도 된다.
랜덤 포레스트가 만들 트리 개수만 신경쓰면 된다.
일반적으로 트리개수가 많을 수록, 계산 비용이 증가하는 만큼, 랜덤 포레스트 분류기의 성능이 좋아진다.
from sklearn.ensemble import RandomForestClassifier
forest=RandomForestClassifier(criterion='gini', n_estimators=25, random_state=1, n_jobs=2)
forest.fit(X_train, y_train)
plot_decision_regions(X_combined, y_combined, classifier=forest, test_idx=range(105, 150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
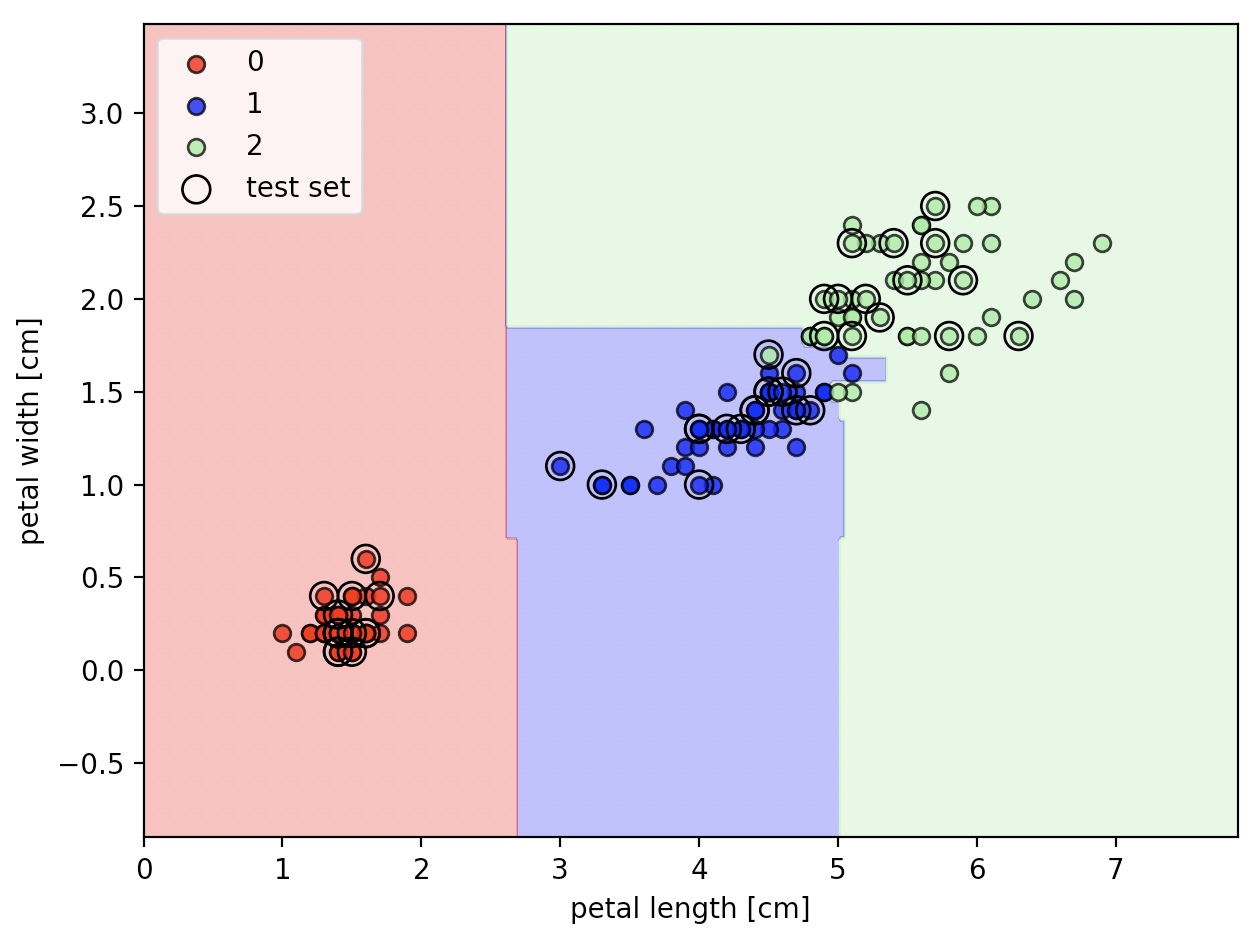
n_estimators 매개변수로 25개의 결정 트리를 사용하여, 랜덤 포레스트를 훈련시켰다.
n_jobs 매개변수를 통해 2개의 코어(컴퓨터의 멀티 코어)를 사용해서 모델 훈련을 병령화 한다.